
Perhaps no area of technology creates more excitement across corporate boardrooms than big data. The ability to use data in a systematic way to inform critical business decisions can provide a significant competitive edge in today’s fast-moving business environment.
Companies across all industries are exploring how data science can improve their operations and profitability. While this trend is not news, behind the headlines business and IT leaders are trying to manage a significant shift in the way data is being collected, analyzed, and reported. What was once a process managed by a select few data analysts, scientists, and engineers in a relatively closed environment, is now touched by everyone from salespeople, to marketers, to finance professionals. Automation and new sophisticated data collection and analysis tools are connecting what was once disparate information silos and integrating data science into every department’s decision-making process.
This is an exciting time to be a part of the data science community, but forward-thinking organizations must also recognize that there is a shared responsibility to ensure data is being adequately protected and managed as it becomes more accessible, connected, and powerful. Data is valuable and could contain anything from credit card and banking details to personal health information, to confidential sales numbers and business performance metrics. Unauthorized usage or disclosure can result in trust-damaging breaches of personal customer information, illegal insider trading, or loss of intellectual property.
Given the high-value of data and its likelihood to be targeted, a thoughtful security approach should be a significant focus for all data-driven organizations. While many security activities will overlap with standard IT and application security practices, it is not enough to assume that existing practices offer adequate protection without a thorough understanding of how data is being gathered, accessed, and used.
In fact, securing big data in a data warehouse can present a significant challenge for organizations more traditionally focused on network security — in other words, protecting systems rather than the data they contain. This blog post examines the data science lifecycle and identifies the key security touchpoints along the process. It is not meant to be a comprehensive guide or to replace an organization’s current security practices. Rather, it can help IT security professionals examine how data is being used within their organization and identify any gaps in their cybersecurity policies and practices.
The Data Science Lifecycle
A thoughtful approach to data science security requires an understanding of how data is used across an organization. Mature organizations will have some form of data governance in place that outlines how it should be collected, shared, used, and retained. This can form the basis of the data science lifecycle. Security teams should review each phase of that lifecycle to determine whether existing security controls are being applied appropriately and where gaps may exist. In doing so, they can build a process-based approach to big data security that aligns controls with actual data usage, and eliminates gaps commonly seen with a network-centric approach.
A simplified data science lifecycle typically encompasses five phases, each of which will have unique security implications.
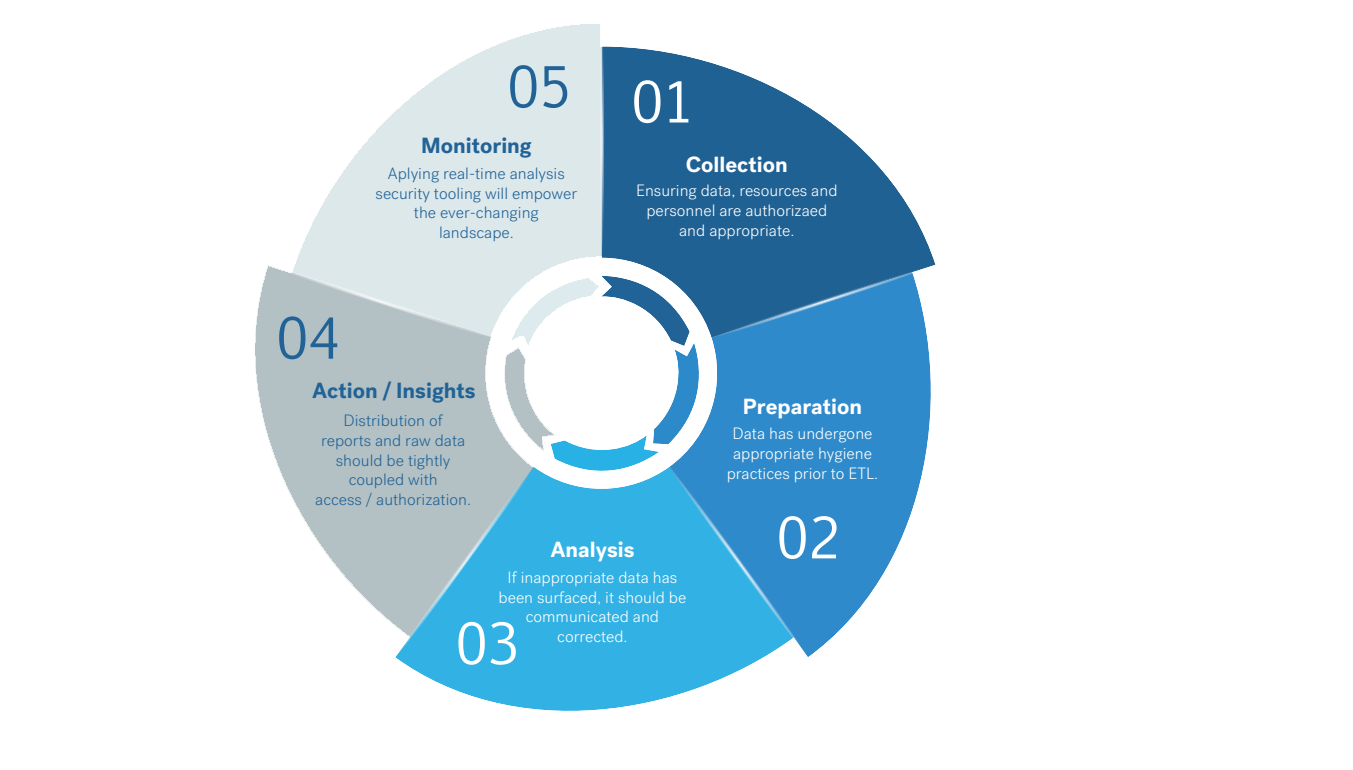
- Collection: Are the appropriate legal, privacy, and compliance controls in place to empower the necessary employees to access data securely?
Example: Data Engineers have received privacy and data security training. - Preparation: Have you validated the data, labeled it effectively, and documented it as part of your data inventory?
Example: You have updated your Privacy Impact Assessment (PIA) to align with the organization’s EU General Data Privacy Regulation (GDPR) compliance processes. - Analysis: Do authorized employees know how to identify an outlier and how to report it?
Example: A free form field or unstructured data that should be encrypted is surfacing sensitive customer details in clear text and your analyst knows how to communicate and to whom. - Action/Insights: Are access and authorization controls adequate to manage the distribution of reports?
- Monitoring: Have you deployed automation to analyze data activity across Collaboration Tools, Applications, APIs, and Services?
Example: The marketing team has enabled third-party plug-ins through click-through software agreements in the organization's Customer Relation Management software, but access has been granted to read-all data.
Key Security Considerations Across the Data Science Lifecycle
While each phase of the data security lifecycle will have unique security needs, the entire lifecycle is supported by an organization’s security policies and practices. There are a number of controls that specifically support big data security that should be analyzed, and potentially strengthened, as part of a review of your security posture. These controls live within a number of IT areas, including application security, access control and data integrity, and data privacy.
Application Security
Your security team should understand what processes, tooling, and frameworks data scientists are using and plan to use throughout all phases of the data science lifecycle, including all commercial and open-source software, as well as applications developed or customized in-house.
Given the high-value data that these applications touch, they must be fully covered by the organization’s product security and vulnerability management practices. These include standard vendor management practices, vulnerability scanning and patching practices, and inclusion in an organization’s secure development lifecycle.
One common mistake seen in data science technology evaluation, especially when working with fast-evolving emerging technology and open-source tools, is an over-reliance on automated security scans.
While automated scanning is an essential element of application security assessment, it is unable to uncover business logic flaws. These type of security issues often lead to exploits and can only be uncovered via manual testing methods, such as pentesting. Fortunately, pentesting is evolving to become more agile and less resource-intensive with the emergence of the Pentest as a Service model, and can be more readily used to address the ongoing assessment needs in fast-moving technology areas like data science.
Access Controls
One of the biggest security challenges in big data is balancing the need to open access to more and more connected data, with the responsibility to protect its privacy and integrity. Many organizations that previously relied on a small team of data scientists working in a relatively closed environment are still catching up to access control and integrity challenges throughout each stage of today’s more open and connected data science lifecycle. This dynamic environment not only creates more potential vulnerabilities for external bad actors to exploit, but also increases the risk of insider threats, especially when one considers the sheer amount of valuable information about an organization the data science team can access.
The risk is not hypothetical. In 2016, a former Capital One Financial Corp analyst was found liable on civil charges that he engaged in insider trading by using non-public sales data from the credit card issuer to buy and sell stocks. The Security and Exchange Commission (SEC) successfully argued that the analyst used non-public data he had access to at work to trade with a significant advantage over the investing public, in fact earning 1.5 million from the illegal trades.
Managing the risk of malicious insiders and unintentional data leakage requires careful consideration of security controls across personnel security, access control, and authorization and data integrity.
Personnel Security
Reducing the potential for unauthorized data usage by trusted insiders is particularly important for any company working with big data, given the high value of the information individuals are authorized to work with.
Standard due diligence during the hiring process is one mitigating factor. However, the assurance process should continue even after onboarding, as both employees' personal circumstances can change, as well as their access levels and roles.
For those with the highest levels of access, organizations should consider periodic background checks. The practice of building an insider threat program should include the implications of highly trusted employees with access to all sensitive data. Clear data usage policies should be communicated as part of the onboarding process and reinforced through ongoing awareness and education efforts.
Access and Authorization
In addition to addressing personnel security, organizations with valuable data need to monitor who has access to what data where. Implementing a policy of least privilege, using strong authentication methods, and maintaining robust and auditable access control procedures is a critical part of mitigating the potential for insider abuse and managing data access.
Endpoint Security
Compromised endpoints are often the primary vehicle for data leakage. Sensitive data can be exposed through device loss or theft, as well as users intentionally or accidentally not following security policies, e.g., accessing information via unsecured wireless networks. As such, extending data protection to the endpoint is critical. This is often accomplished by creating personas for the data team, coupled with authentication profiles and insider threat monitoring.
Considerations should include:
- Two-Factor Authentication (2FA) - For all services, while it is not likely practical on the endpoint itself, having 2FA in place is becoming less of a battle for security teams.
- Virtual Private Networks (VPN) - Establish secure communication channels, which can also allow for more effective monitoring. However, the security team must be mindful of how VPN software works as it may create friction if it interferes with the ability of Data Engineers to deploy tools without cumbersome new configurations or changes.
- Mobile Device Management (MDM) - Platforms to set, monitor, and enforce device security policies.
- Data Loss Prevention (DLP) - Solutions to effectively prevent or monitor and alert if there is movement of sensitive data to unauthorized endpoints.
- Dedicated Environments - Roll out, in partnership with the data team, virtual closed environments where data analysis can take place, which would avoid data living on the employee’s endpoint.
Data Hygiene
As data science moves into a more strategic business function, data scientists and business managers are asking for more and more access to information and the systems that support its collection, analysis and reporting. Security teams seeking to both enable the business and protect its data need to apply appropriate data hygiene practices to empower teams without compromising security or the integrity of the data in use.
Key data hygiene practices should include, at a minimum, the following:
- Data Availability - Access and authorization models are a must, and organizations must also apply the correct controls to have data available only to the correct employees. As many organizations shift to cloud-based strategies and employ more Software as a Service (SaaS) solutions, sprawl can have a detrimental effect as more and more data needs to be available.
- Data Inventory / Discovery - Generally, the practice of knowing what data is where is important to any organization to enable business processes, either through automated or manual means. For privacy and security reasons there is heightened awareness as more individuals are empowered with the right to request the removal or correction of their data. Without an inventory, there is no option to honor these requests.
- Retention Policies and Deletion Procedures - With ever-growing privacy mandates impacting companies globally for handling certain citizens' personal data, employing the practice of minimization is in most organization’s best interest. This means establishing clear guidance and an enforcement process to effectively destroy data at the necessary cadence.
- Traceability - As the data team transforms, changes, and moves information in real time, it is important to understand who is doing what for data freshness. Similar to the Logging/Monitoring and Auditing functions, organizations should have a clear, factual log of actions taken. One of the key practices is to enforce requirements of individually named access, which means no shared accounts or re-used API keys.
- Logging/Monitoring - Effective logging for access and authorization is necessary to better enable the auditing process. Further, there may be ongoing analysis through an insider threat program based on privileged user-monitoring for the data science teams to sample queries. Access levels for sensitive information should be reviewed on a cadence in line with the needs of the business and corresponding risk levels.
- Auditing - Being able to review who is accessing data and what they are doing with it is not only helpful for monitoring for insider threats, but also for identifying patterns that could signal an external attack. The faster these indicators of compromise are identified, the greater the opportunity for the security team to mitigate the attack, limit damage, and begin remediation. This is frequently accomplished by sharing threat intelligence feeds with security analysts and incident response teams. In fact, this is the area that most security teams have experience in working with big data and they may be managing their own closed-loop data science lifecycle. Ensure that security extends to this process, being mindful to preserve auditing ability so that security teams are also covered by the same security policies and procedures as the rest of the data science organization. Robust auditing capability will help ensure that someone is “watching the watchers.”
Encryption
Data should be encrypted both at rest and in motion, and it is imperative that encryption extends to endpoint devices. Security teams should follow encryption best practices for sensitive information and be mindful of ensuring proper key management, as a poorly performing key management system will compromise even the strongest encryption algorithms
For some types of structured data, such as payment information, tokenization may be the best data privacy mechanism. Tokenization involves replacing sensitive data with data that can't be used by unauthorized parties. It replaces original data with randomly-generated characters, known as token values. When an authorized user needs to access the correct data, the tokenization system replaces the token value with the original data.
Masking is another data protection option that is similar to tokenization in that sensitive information is replaced by random characters, but unlike with tokenization, there is no mechanism for swapping the data back to the original format. Dynamic data masking is an interesting option for data science as it allows you to show specific users' original data, while “masking” that data for others without the same level of permissions.
Privacy
Data privacy practices typically revolve around the important goal of protecting data no matter where it exists within the organization. The use of encryption is considered standard practice, and many organizations are also taking advantage of tokenization and masking technology. Endpoint security practices have also proven critical to ensuring data privacy especially as security teams work to empower business leaders to access important data where and when they need it. As such, any organization working to secure the big data lifecycle should carefully review its encryption and endpoint security policies to ensure they offer adequate protection across the data science lifecycle.
Summary
Data science is a rapidly evolving discipline and while it is an extremely exciting time to be on the front lines of data-driven business, security teams may find themselves doing a bit of hand-wringing as more and more sensitive and valuable data becomes accessible and connected across organizations.
Trying to plug holes as they arise is the equivalent of security whack-a-mole and most often a game that can’t be won in a field as dynamic as data science. Rather, security teams should seek to take a process-based, lifecycle approach to big data security — first seeking to understand how data flows through their organization, and then identifying and closing gaps in existing security policies and procedures.
By proactively strengthening the data security process across the data science lifecycle, security teams will greatly improve their ability to mature their defenses alongside the rapidly growing field of big data.



