




Employees are working from home and other non-office locations in record numbers. Cobalt is no exception — we are now a remote-first company. We also have the Cobalt Core, our pentesters across the world, mostly connecting from home. While this is a blessing for workers, it’s also a curse for those looking to keep them secure. Instead of sitting down at the office and connecting through a meticulously configured and monitored corporate network, we’re now connecting through the coffee shop or our home Wi-Fi that might not be so safe.
The primary danger to those working from home is known as a Monster-in-the-Middle (MITM) attack. When colleagues access anything on the internet, their packets travel along a predetermined route, bouncing between dozens of computers before reaching its destination. MITM attacks occur somewhere within that route, silently intercepting and even replacing data as it flies along the wire. The key takeaway here is that the attacker has to be somewhere along the route.
There are many places they could decide to attack:
- The servers of the website employees are connecting to
- The network of the website’s servers
- The internet service provider (ISP) of the website
- The Tier-1 or Tier-2 ISPs that connect end-user ISPs together
- Employees’ ISP
- Their network
- Their computer
The weakest link here is almost always their network since it’s designed to be convenient to connect to. In corporate environments, the network can be heavily secured. But most home networks are barely secured and public networks are completely insecure by nature. This means that with the worldwide shift to working from home, we’ve also created a massive attack surface across remote companies worldwide.
Unfortunately, it isn’t Hollywood magic for someone to find the address of a privileged employee, sit outside their house, crack their Wi-Fi password, and intercept all their data. Depending on how old the router is, it can actually be quite trivial and can be done with commonly found software that even the most beginner of hackers can use. Public networks like coffee shops are even worse since there’s no Wi-Fi password to break.
You probably know the solution: a VPN. Originally a technology designed to make your computer part of a corporate network, it is now being widely used to connect computers to the internet while keeping intruders along the route out. There are many providers of consumer-grade VPNs for this purpose, but we quickly found that anything that was designed for business and met our needs was exorbitantly expensive for our simple use case.
We didn’t need to connect our laptops to a corporate environment or have advanced routing — we just needed to get to the internet safely from anywhere in the world without heavily affecting performance or reliability. And so Mantis was born: a globally distributed, highly fault-resistant OpenVPN-based network for securely connecting employees to the internet.
Our VPN Requirements
We outlined some basic needs when building Mantis.
- Public internet connectivity: We don’t need to connect to a corporate network, we’re going straight to the internet.
- Global distribution: Our employees are spread across the globe. To ensure performance isn’t degraded, we need VPN servers in all our major locations.
- High availability: Employees should be able to stay secure 24/7/365.
- IdP authentication: Access should be controlled via our identity provider
- Ease of use: Our employees shouldn’t have to worry about setting up their VPN or connecting to the right VPN.
- Multi-tenant: Our pentesters should have a separate network path from our employees.
- Observable: We should be able to quickly determine and troubleshoot the state of the VPN and any individual connection.
- Consistent and exclusive IP addresses: We have our pentesters use VPNs in part to ensure all of their traffic comes from a known set of IP addresses so our customers can configure their firewalls appropriately
- DDoS Resistant: Since our entire company connects through this VPN, it makes it a juicy target for a DDoS. We need to make sure we can withstand attacks.
While there are some business-grade VPN providers that have all of the above, we decided that they simply cost too much and were too complex compared to our requirements. Instead, we’ve implemented the fantastic OpenVPN project on a global scale.
The Basics
At a high level, Mantis is simply a combination of Google Kubernetes clusters spread across the globe running an OpenVPN wrapper, an API for issuing PKI certificates from Google Cloud’s Private Certificate Authority, and a client application for configuring Tunnelblick.
We currently have two different VPNs — one for our pentesters and one for Cobalt employees — but they both live within the same Kubernetes clusters. We achieve full network segmentation by having separate load balancers, NAT gateways, and node pools.
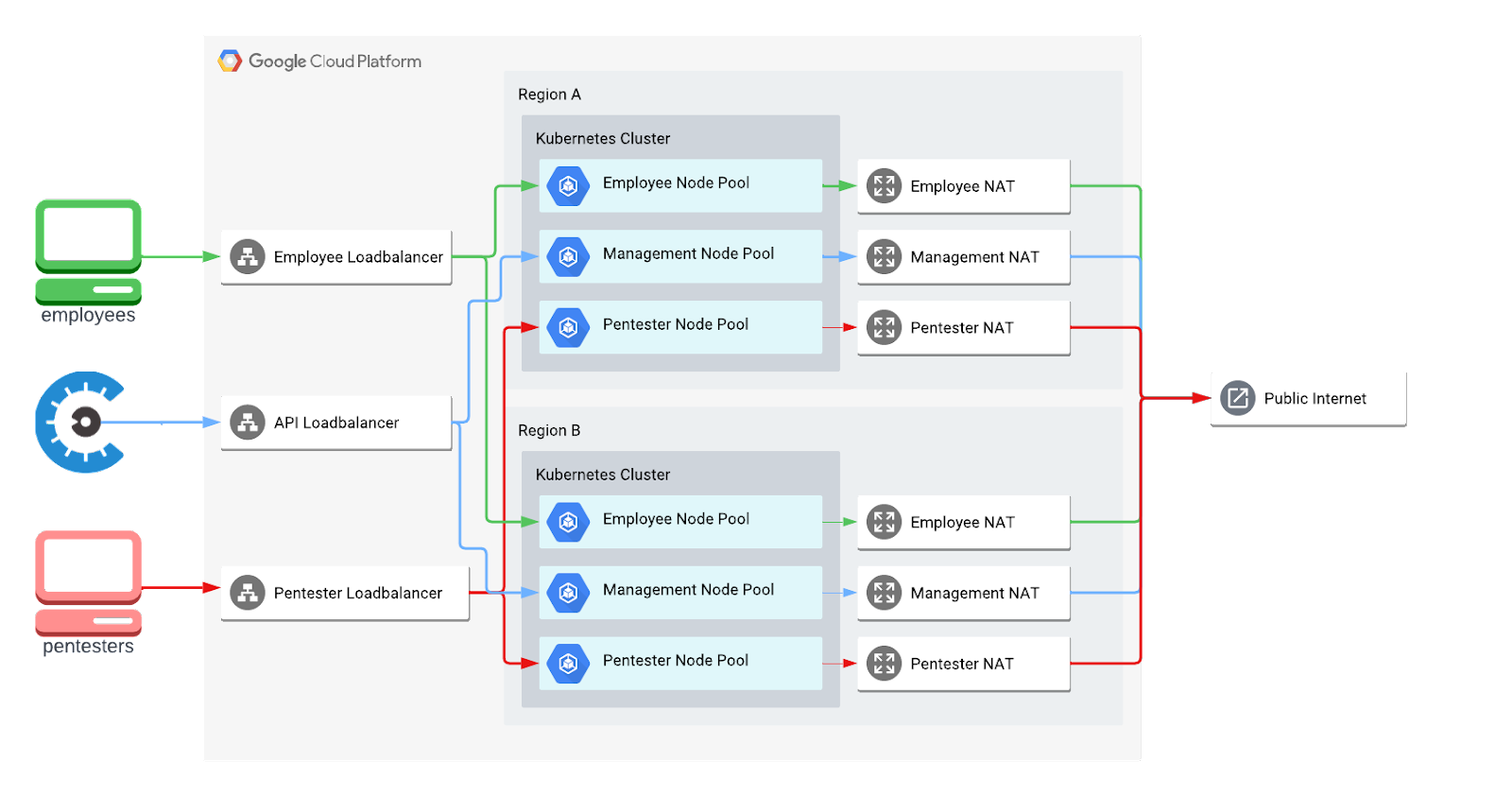
However, connecting these dots to be production-grade and global-scale required the use of a few new Google Cloud features, various open source and in-house software, and some odd techniques.
Following this are some of the challenges we overcame and decisions we made in the 6 months it took to build Mantis.
Private CAs: Securely Issuing Credentials
With OpenVPN, clients and servers identify themselves using PKI. In short, the server and client certificates must both be signed by the same Certificate Authority. Nowadays it’s quite trivial to run your own local certificate authority and that’s exactly what we were doing for a few years prior to Mantis: you would make a request on Slack and someone from the IT team would issue a full configuration file to our VPNs.
However, having our IT team manually generate the client configuration and send it over Slack, while convenient for our employees, was not the best approach for implementing PKI. Not only was it a waste of time due to the manual work involved, we had to have access to the root CA key to generate keys for others, which meant that if someone in the IT team left Cobalt we’d have to rotate all of our keys. The best way to implement PKI is having a client send their public key and then from that a certificate can be generated and sent back to them.
Of course, expecting all your employees to generate public keys in the terminal and copy all the info correctly into the OpenVPN configuration file is a tall order. Some automation had to happen!
For this, we decided on creating an API that layers over Google's Private Certificate Authority for issuing certificates to both our servers and clients. This API is consumed by the wrappers we wrote around OpenVPN and Tunnelblick and integrates with Okta for client authentication. Not only are the certificates now transmitted securely, they’re also fully auditable and revocable with a publicly hosted Certificate Revocation List (CRL).
One important thing to note about CRLs and OpenVPN: you have to download the CRL manually. OpenVPN does not know how to retrieve the CRL of a certificate. This is one function of our wrapper: downloading the CRL automatically.
One-Click: Ease of Use is Key
To promote the use of our VPNs at Cobalt, we had to make it as pain-free as possible. To this end, we wrote some in-house software that we deployed to all of our laptops. Every month, our laptops request that we sign in via Okta. Once signed in, it will communicate with our APIs to issue a PKI certificate for connecting. Tunnelblick is then automatically configured and connected to the VPN.
We also needed to make it as non-intrusive as possible since many of our employees might be in Zoom calls when it’s time to renew their configuration. In order to do this, we made use of Mac’s notification center and simply pop up a notification. There was one particular 'gotcha' though — only signed applications can make notifications and we didn’t want to wait for our Apple Developer Certificate. To temporarily get around this, we made use of the alerter project which is a signed application that can make notifications for your unsigned application. A clever little workaround!

By reducing all the manual steps of requesting and installing VPN certificates down to a single click and a login, we increased voluntary usage of our VPNs by 400%, overall improving the security posture of our company.
We recommend that you put ease of use above all else as it will increase adoption. The most secure VPN is useless if it isn’t being used.
TCP Meltdown: A Necessary Evil
While the community version of OpenVPN has absolutely no concepts regarding clustering or failover, thanks to OpenVPN being mostly stateless, we simply had to create multiple copies of the server and route clients to them. As long as all the VPN servers are identically configured, it shouldn’t matter to the client which server they connect to. We can throw a bunch behind a load balancer and call it a day.
But we wanted to take this a step further and make it so the client doesn’t have to worry about what region they’re connecting to either. To accomplish this, we made use of Google Cloud’s TCP Proxy Load Balancing which provides a single, global IP address to multiple backend pools.
However, this also means OpenVPN has to run in TCP mode as global routing is TCP-only on Google Cloud. This has one major drawback that we decided to accept for now: unstable connections will become even slower due to a phenomenon called TCP meltdown. Long story short, by tunneling TCP over TCP, you have two congestion control methods conflicting with each other. You can find more info about TCP Meltdown on the OpenVPN website.
We also decided on using TCP over port 443 to ensure that our pentesters across the world could access the VPN. Some countries block or slow VPN traffic, but when it runs in TCP mode over port 443, it is indistinguishable from regular web traffic.
If you don’t have these requirements, we recommend you use UDP for OpenVPN.
Split Tunneling: Keeping Zoom Stable
For the most part, the effects of the aforementioned TCP meltdown are unnoticeable when you’re simply browsing the internet. However, we’ve found the effects can be significant during video calls. In order to avoid this, we need to have Zoom bypass the VPN. Luckily, it is quite easy to do this with OpenVPN if you know the IP addresses.
-1.png?width=834&height=482&name=pasted%20image%200%20(1)-1.png)
Essentially, we have to push one route per known IP range. The net_gateway signifies that any traffic destined for that IP range will be routed through the client’s default network gateway instead of the VPN. The last number is known as the metric and is essentially a priority level if multiple routes match a given IP.
You can find a full configuration example here..
PROXY Protocol: Keeping the IP Address Real
When you route through a load balancer, the VPN server sees the load balancer’s IP address instead of the real client IP. While HTTP has a header that can pass along this information, TCP itself wasn’t built with this in mind. This is where the PROXY Protocol comes in. In short, a load balancer passes along this information after the connection starts but before the real data begins. The only problem is that your application has to understand the protocol and OpenVPN does not. It will see the first packet from the PROXY protocol, get confused, and disconnect you.
Enter go-mmproxy: a thin proxy that understands the PROXY protocol and rewrites the packets so it appears as though it came from the original IP. This way, OpenVPN’s logs and routing table status shows the original client IP. It is a very clever trick that enables us to easily correlate the real IP addresses of clients for auditing purposes.
You can use mmproxy for any application where you can’t directly support the PROXY protocol, so long as you have the NET_ADMIN capability.
Spot VMs: Massive Savings for a Non-Critical Workload
Google Cloud recently released an offering that made Mantis cost-effective. They are known as spot VMs, which in short means that Google can shut down our Kubernetes nodes at any time in exchange for greatly reduced pricing. For some workloads, this would be unacceptable. But for a VPN simply used to access the internet, it’s no problem at all.
By having multiple replicas in every region, the worst that happens is a client is quickly reconnected to the next healthy server. In our experience thus far, on average the nodes only get reclaimed twice a month and usually on off-hours, so the effect is almost unnoticeable. However, this could vary greatly based on region and by the time you read this article so test it out yourself before moving to spot nodes!
Thanos: A Single View into Prometheus Across the World
Having a globally distributed system makes an in-depth monitoring system even more necessary, yet also more complex. We wanted to use Prometheus, but the federation model was too complex and lossy for our needs. We wanted to be able to dive into as high-resolution data as possible, as far back as possible, while retaining performance and high availability, regardless of how many regions we add.
To accomplish this, we made use of the Thanos project to supercharge Prometheus. Thanos is essentially a drop-in layer that is compatible with the Prometheus API and proxies requests to several other Prometheus nodes. Anything that can query from a Prometheus node can query from a Thanos querier, including other Prometheus nodes for federation. Recursion!
Because of the spot nodes, our Prometheus nodes might go down at any time and stop collecting data, so we have two replicas of Prometheus running in each region and collecting their own full copies of the data. This data is then retrieved and deduplicated by Thanos and finally processed by Grafana for monitoring and alerting.
What you see below is returned by over 20 different Prometheus nodes spread across the globe, all being queried at once thanks to Thanos.
.png?width=1600&height=838&name=pasted%20image%200%20(2).png)
Despite the distribution of our Prometheus time series data, queries still return lightning quick due to the divide and conquer approach.
Monitoring OpenVPN: Custom Prometheus Exporter
Prometheus is an extremely powerful tool with an even more powerful ecosystem. It has the concept of an ‘exporter’ which is a daemon that runs alongside your services and applications and presents a REST endpoint with the current metrics. Prometheus scrapes these REST endpoints periodically to build its time series data. You can monitor almost anything with exporters and pretty much every well-known application has an exporter for it already.
Unfortunately, the only OpenVPN exporter we found didn’t quite fit our needs. So we did what any good DevSecOps team would do and we built our own! By reading the status log saved to disk by OpenVPN, you can track connections, data transfer rates, client names from the certificate’s common name, and more. We combined this information with GeoIP queries to build a map of where everyone is connecting from to determine whether or not our global routing was working properly. All of this data is stored within Prometheus thanks to its flexible labeling system.
If you have an application you want to track metrics for, even your own applications, know that writing exporters is a trivial task.
Multi Cluster Networking: Global Services Made Easy
When you want to run Kubernetes across regions in Google Cloud, you have to have a completely separate cluster per region. While it’s extremely easy to set up Google’s load balancers directly from Kubernetes, there wasn’t any easy way to do so for multiple clusters that would use a global load balancer. You also have to worry about setting up a service mesh that can cross clusters if you want applications in your clusters to talk to each other (i.e. our Prometheus nodes)... Or do you?
Recently, Google released two important GKE features we made use of: multi cluster services and multi cluster ingresses.
We wanted to make sure that our API was always available, so we decided to replicate it in every region our VPNs run in. We did the same for our Prometheus instances as well as Grafana. Multi cluster ingresses are a GKE-native way of defining services across clusters that should be accessed via a global L7 load balancer. By putting Grafana and our API behind the multi cluster ingress, we easily created globally replicated and distributed services that were accessible from a single URL.
Another obstacle we faced was making it so we could access our Prometheus data from anywhere across the globe using the closest Grafana instance. For this to work, every single Prometheus instance had to be accessible by every Grafana instance. Instead of implementing a complex service mesh, we made use of the brand new multi cluster service feature. No matter where you are in the world, you can connect to a nearby Grafana instance and your metrics requests will be sent out to every other cluster.
Both the multi cluster ingresses and multi cluster services are configured directly inside of Kubernetes via custom resource definitions.
Cloud NAT: Consistent IPs for Outgoing Traffic
In many of our pentests, customers require that the traffic come from a specific set of IP addresses so they can allow it through their firewalls or audit the activity. Therefore we need our pentesters’ outgoing VPN traffic to come from known IP addresses. In order to accomplish this, we make use of NAT gateways and discontiguous multi-Pod CIDRs.
NAT gateways are straightforward: you assign them an IP address, attach them to your private subnets and any internet traffic will come from the assigned IP. However, until multi-Pod CIDRs were supported, it would have not been possible to make two node pools use two different NAT gateways like we needed to keep our pentesters and employees separated. All node pools had to share the same address range and thus the same NAT gateway.. until now!
With multi-Pod CIDRs, we simply create a secondary IP range for each VPN and assign the respective node pools to them. This is the missing link to make a NAT gateway specific to certain node pools and not others. While it’s still several IP addresses due to NAT gateways being regional, they are static and will remain the same unless we add new regions. As a result, we can easily communicate these IP addresses in various places to our customers.
HMAC Signatures: Secured from the First Packet
A big problem with having a VPN is that it is by nature publicly available on the internet and thus subject to denial of service attacks. This is a big problem since that means we’ve effectively given hackers a way to take down our company’s entire internet.
Luckily for us, Google Cloud’s load balancers come with DDoS protection built in. But there’s another trick up OpenVPN’s sleeve that can help withstand denial of service attacks: HMAC signatures.
By sharing a pre-made key between the clients and servers, you can enable HMAC for signing the SSL/TLS handshake messages. Any packets that aren’t signed are immediately dropped without further processing. This prevents malicious actors from communicating with your VPNs whatsoever without first having gained your TLS key.
We ran an internal pentest against our VPNs with a specific purpose in mind: test the DDoS protection. No matter what tools were used, thanks to the combination of Google’s DDoS protection and OpenVPN’s HMAC signatures, our VPNs remained online with no noticeable effect. While a significantly larger DDoS could probably cause some issues, we’re pretty well protected against a run of the mill attack.
Terraform: Deploying Mantis in One Command
One of the problems with running lots of Kubernetes clusters is ensuring that everything is applied consistently across them. Imagine having to do `kubectl apply` on 12 different clusters every time something changed, or even worse, deleting things you no longer need!
Here at Cobalt, we’re huge fans of Terraform. Almost everything we do is Terraformed, and Mantis is no exception. Matter of fact, Mantis is probably the most pure usage of Terraform we have! Absolutely everything is deployed via Terraform including our Kubernetes manifests.
There are various tools for accomplishing multi-cluster deployment like ArgoCD, but since we were already using Terraform we decided to keep things simple and manage all of Mantis’s Kubernetes manifests from Terraform too. It’s a lot of boilerplate since you can’t for_each providers, but it’s much easier than the alternative of manually applying.
.png?width=688&height=622&name=pasted%20image%200%20(3).png)
To ensure that Mantis was reusable and could have both a production and development environment, we also modularized the entire thing. We can easily spin up entire Mantis clusters across the globe inside of any GCP project in a single command thanks to the power of Terraform.
Wrapping Up
So now you’ve learned some of the challenges we had to overcome to build Mantis. They were wide and varied — networking, security, monitoring, ease of use, and more. It took nearly six months to build, but we’ve been serving hundreds of clients concurrently across the globe for four months now without a single hiccup. Mantis has proven to be a reliable solution for getting our employees and pentesters to their destination securely.
In today’s work-from-home world, one of the best things you can do is use a VPN to securely tunnel you to your destination. It doesn’t have to be complex or complicated and all the pieces of the puzzle are out there — you just have to bring them together.
We hope some of this was insightful and that you can use some of this in your own projects or even your own version of Mantis.
Before you go — we’ve been considering open sourcing the Mantis project, rebuilding it from the ground up to be usable by other companies. If you’d like to see this happen, please drop us a line at mantis-oss@cobalt.io.



