We've talked about the stages of the pentest lifecycle, now let's look at the life of a bug.
Bugs have a life. They are born and then they die, both in the real world and in the security world. However, in the security world, we need a better way to understand the lifecycle of these bugs (vulns) so that we can more effectively eliminate them.
With this post I’d like to present a way to better understand bugs, from their origin until their death. I’ll do this by introducing the idea of a security bug pipeline.
The goal is to establish a framework and common language to think about bugs as they pass through a pipeline from Find-to-Fix.
Why we need a new way to look at bugs
Throughout its life, a security bug passes through different stages — found, validated, prioritized and eventually fixed by a developer.
A new bug is less mature compared to bugs which have been validated and risk-classified. Yet, in software security we lack a common language to differentiate an early-stage bug from a mature, validated bug.
The lack of differentiation leads to noise and inefficiency. When bugs aren’t killed effectively, companies become vulnerable to hacks. The consequences are dire.
We need to be able to better differentiate and manage bugs through their lives. We need to be able answer questions such as:
- Can we reproduce the issue?
- Are the bugs qualified?
- Is there a fix for it?
- Which are the most risky?
- How can we prioritize the security issues?
The Find-to-Fix framework
A standardized framework for dealing with bugs can greatly transform the security industry.
Just look at how adopting a framework has transformed Human Resources. There’s the “Hire-to-Retire” process, which helps HR successfully recruit and retain employees.
And of course the pentest lifecycle, which assists companies conduct security testing more efficiently.
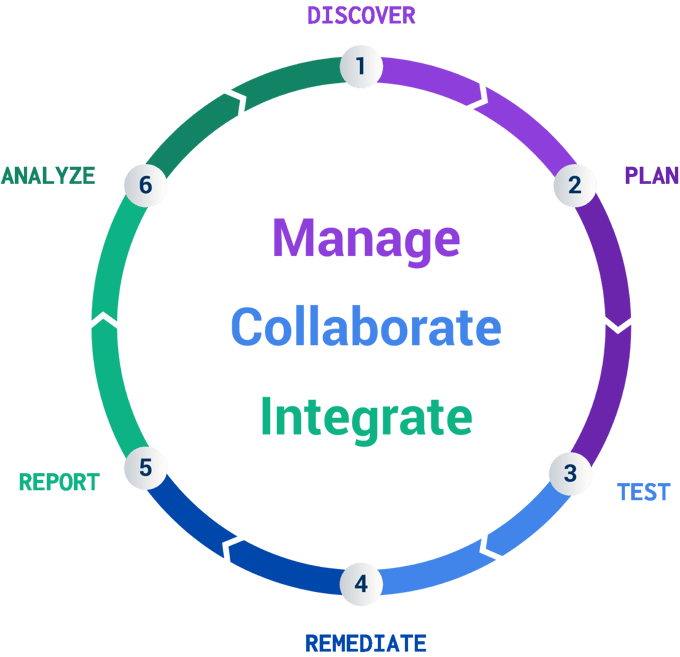
For those of us in software security, I’d like to introduce the framework of a security bug pipeline from Find-to-Fix.
A bug pipeline represents bugs at different stages of life. The stages are:
- Find: Discover the bug.
- Validate: Check whether the bug is valid.
- Prioritize: Evaluate a group of valid bugs and understand which to fix first.
- Fix: Squash the bug.
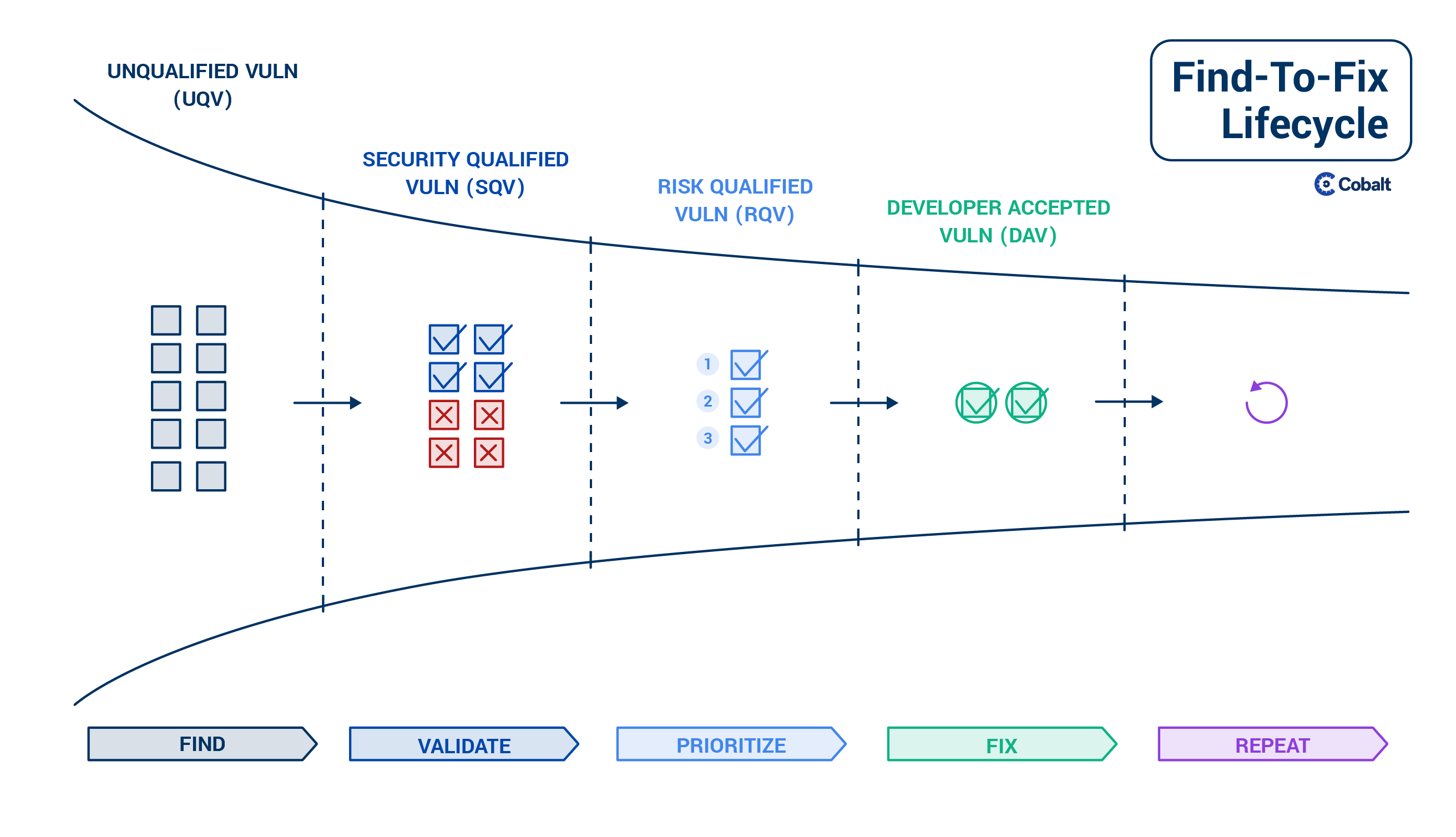
Now let’s take a closer look at each stage in a bug’s life.
Find
Some of the most common sources for new bugs are:
- Vulnerability scanners
- Vulnerability assessments and penetration tests
- Responsible disclosure and bug bounty programs
- Independent third party (customer, vendor)
However, the challenge is that these different sources produce bugs which are unvalidated. For example, vulnerability scanners and bug bounties have weak filters causing significant noise in the Find stage. Typically the invalid bugs from scanners are 85% of total results, and for public bug bounty they’re around 90%.
This means that many bugs from scanners or bug bounties are primarily unqualified vulns (UQVs). Security teams need to validate them before taking further action.
Validate
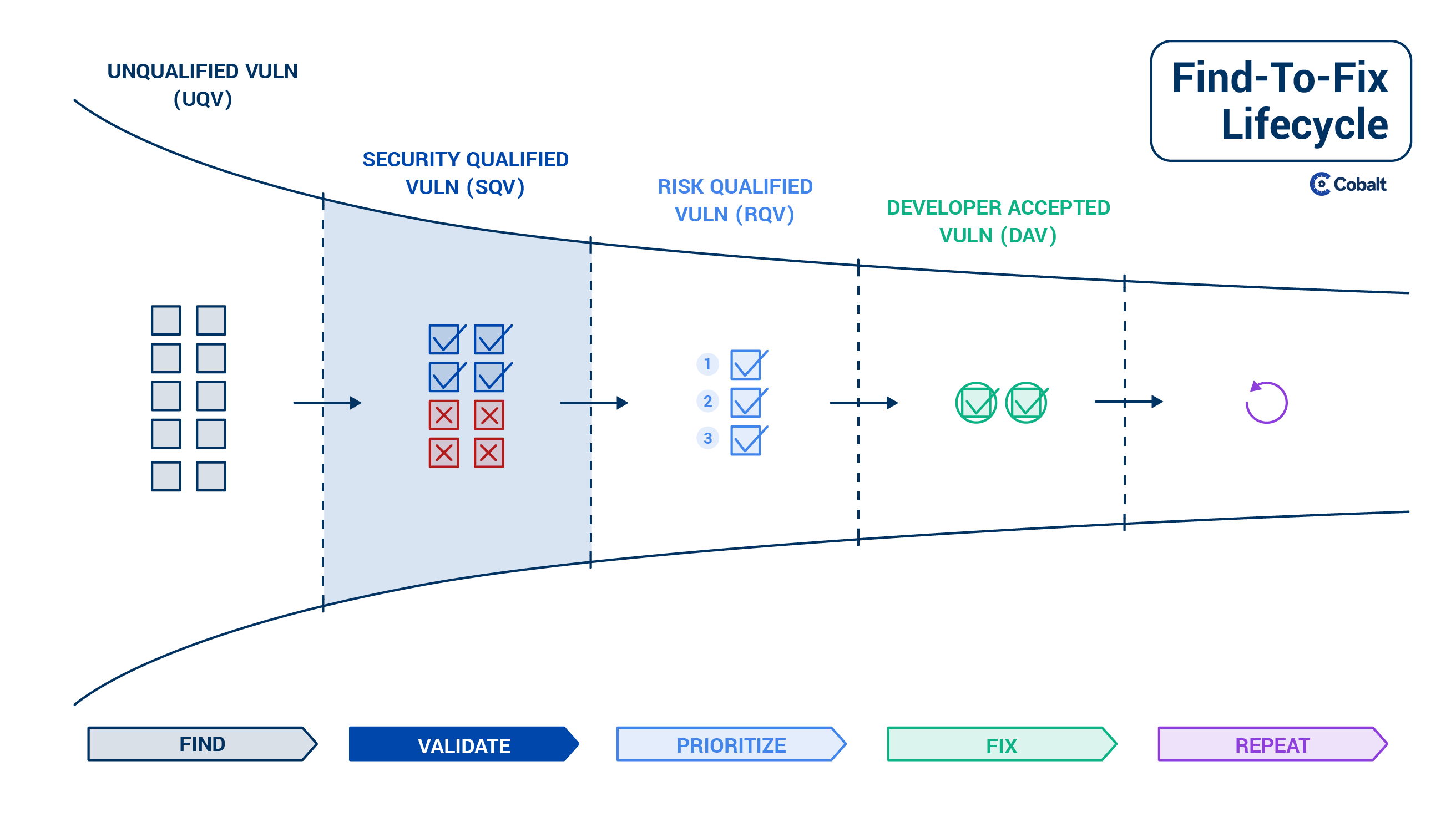
While finding bugs might be fairly easy, it can take some time to validate an application’s various potential bugs.
Once a security engineer receives a new security bug report, the first thing they will often do is confirm whether the issue is actually valid and can be reproduced. The goal of validation is to remove the noise from vulnerability scanner or bug bounty results. For example, maybe the report highlights a bug the security team already knows about, but has not yet fixed. In this case the new bug is a duplicate of an already known issue.
The validation step is extremely important and has to happen before assigning bugs to developers. If you assign several false positive bugs to developers to fix, you end up in a 'Crying wolf' situation which builds disconnect between the security and dev teams.
At the end of the Validate stage, you end up with a group of bugs which then need to be prioritized.
Prioritize
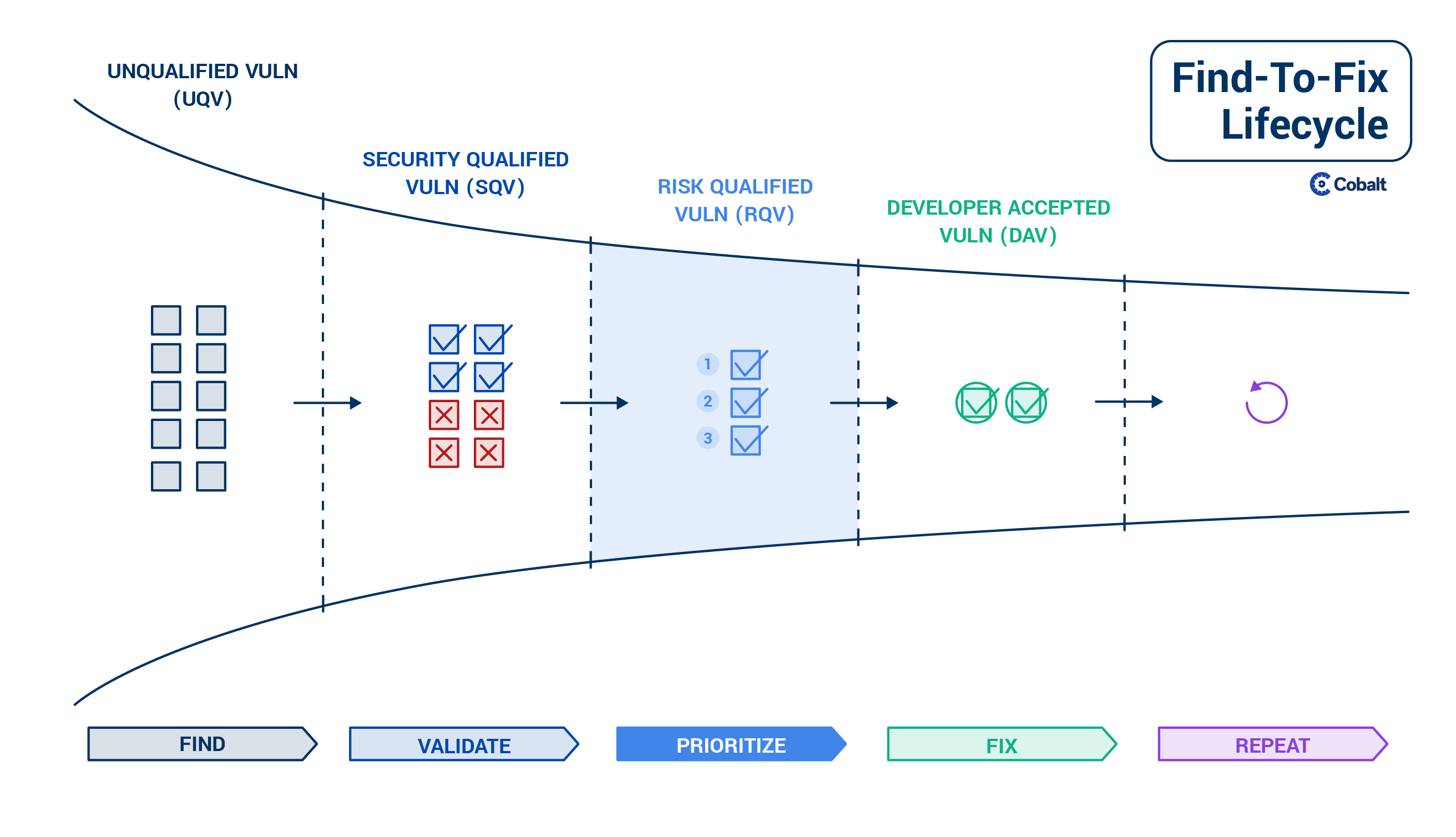
In order to move from validated to fixed, bugs need to be prioritized.
Though the prioritization process in your organization might be informal, not documented, and not visible, this is a necessary step. Proper prioritization saves time and prevents security catastrophes.
A scarce resource for most businesses is their engineers’ time. Therefore is it tremendously valuable to prioritize this time and figure out which security issues are really important, and which you can address later.
Also, the risk of some bugs and their threat level might be much higher to one organization compared to another. Through prioritization, one can decide which risky bugs need to be fixed faster and which can wait. For example, are you going to focus your energy on the 100 low priority XSS or on the authentication flaw which allows an account takeover?
However, quantifying risk remains more art than science. It requires creativity and judgment. Several vulnerability scoring models are available to help prioritize vulns such as the OWASP Risk Rating Methodology and CVSS. It’s important to consider both these frameworks, and where the vulnerability resides within your systems. Understanding this context requires judgment and creative thinking. Therefore this task cannot be automated and is often done by people —engineers or security engineers who also understand the business context of how a vuln can be exploited.
After bugs are prioritized, we can finally move to fix them.
Fix
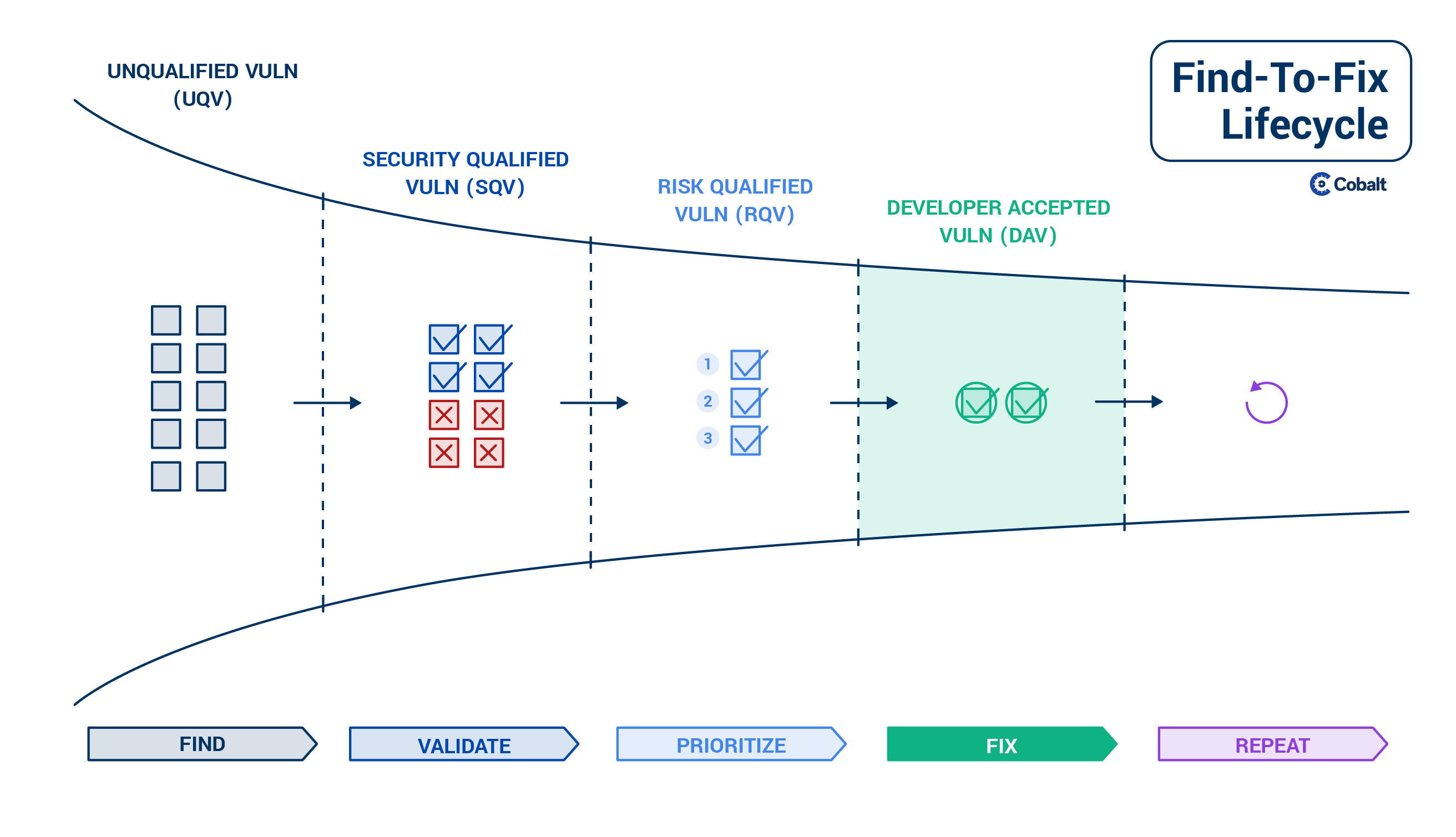
Now that the work has been done to find, validate, and prioritize bugs, we can fix them. It’s here that we get the real value of the entire process.
Fixing a bug requires a hand-off from the security team to a developer who is able to update the affected code. The prioritization exercise in the previous step is critical for this hand-off to be effective. If security teams throw too many bugs over the fence to the development team, this handshake will not work well.
Ideally the dev team then accepts to work on these prioritized vulns and becomes responsible for fixing them within a given timeline. In this stage one can speak of ‘Developer Accepted Vulns’, which is then the final stage of the bug life cycle.
Looking back at a bug’s life from Find-to-Fix
Through this post, we’ve examined a bug’s life in different stages as they are found, validated, prioritized and eventually fixed.
With the Find-to-Fix security framework, we can better understand the life of bugs so that we can more effectively eliminate them.
My hope is that we as an industry can adopt a common framework and language to understand bugs. Though our security workforces are becoming more distributed, our shared knowledge should become more centralized.
More to come
In future posts I will dive into how to measure effectiveness and key KPIs across different stages in the bug pipeline.
In the meanwhile, if you want to join in on making an impact in security, please:
- Share this post with fellow security peers so that we can collectively improve our understanding of bugs.
- Let us know your thoughts on this framework by leaving a comment on Cobalt's Linkedin.
- Follow our Cobalt blog to stay up-to-date on hot security topics.
Together, let’s squash those bugs and better ensure security in the modern world.
Thanks to Jeff Forristal, Richard Seiersen, and Caleb Sima for having read drafts of this post and providing valuable feedback and comments.